Open source · Supply-chain security
Be one of the eyes: catching supply-chain attacks with a 12B model on your laptop
Routine package review is a waste of a frontier model’s intelligence — and a job a 12B open model can do, offline, on hardware you already own. Here’s the proof, and an invitation.
Software supply-chain attacks keep landing for an unglamorous reason: there aren’t enough eyes on new package releases, fast enough. An attacker ships a compromised version of a trusted package, and it’s pulled into thousands of installs before anyone looks at the diff. The window between “published” and “caught” is where all the damage happens.
The reflex answer is to throw a frontier model at every release. But that’s expensive at firehose scale, it leaks the very code you’re inspecting to a third party, and it gatekeeps participation behind an API budget. It’s also, frankly, a waste of intelligence: deciding whether a new build of a logging library added a credential-stealing postinstall hook does not require a model that can also pass the bar exam.
So here’s the bet behind DiffWatch: what if the per-release reviewer ran on the laptop you already own — offline, private, and free — so that anyone could be one of the eyes? Two open-source tools test that bet: PyDiffWatch for PyPI and npmDiffWatch for npm. Same design, same philosophy. Here’s what happened when I ran the npm one.
First, does it actually catch anything?
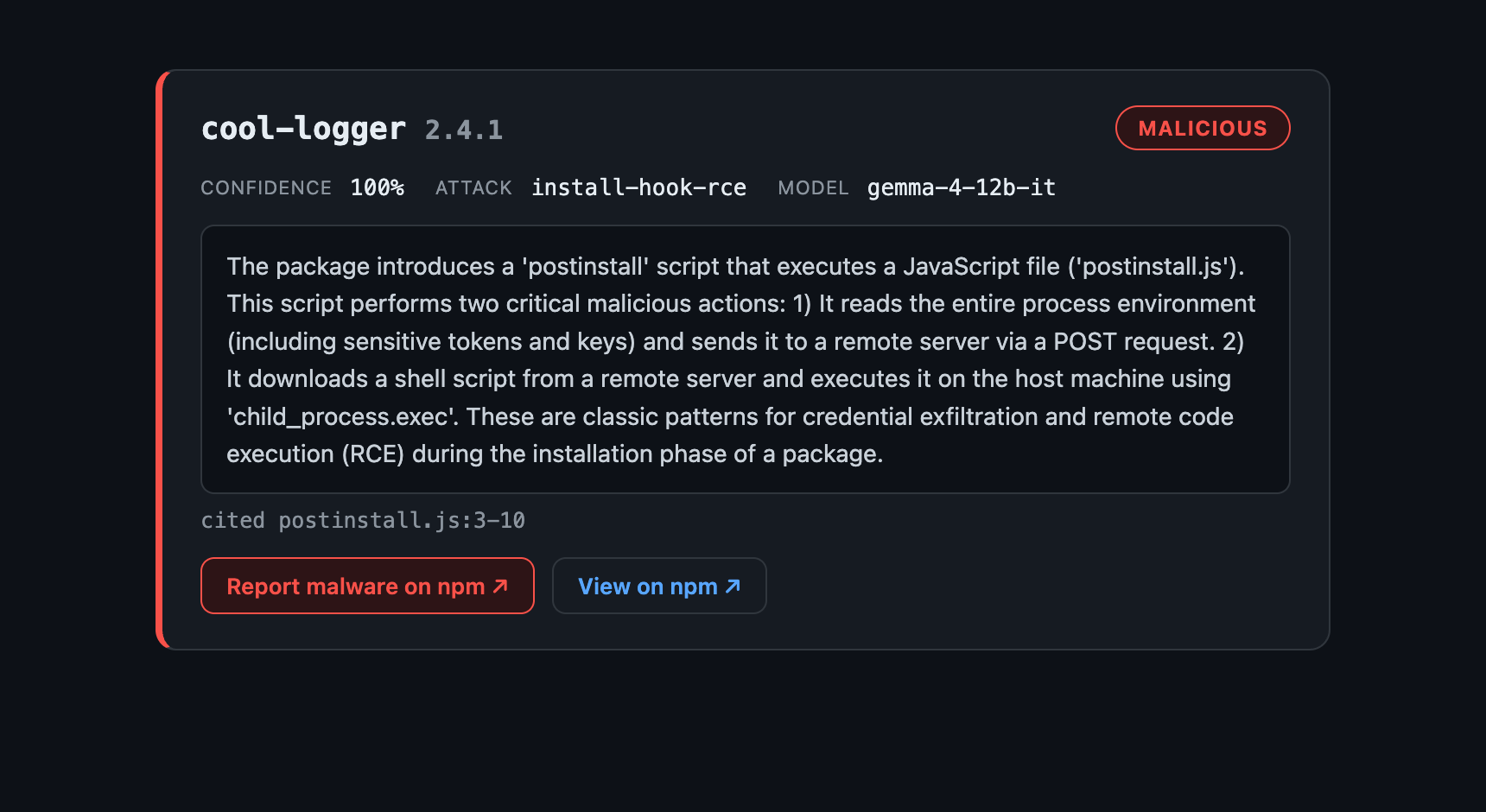
I built a planted malicious package — a synthetic test fixture, never published to npm — that does exactly what a real install-time attack does. It adds a postinstall hook that reads the entire process environment, POSTs it to a remote server, then downloads a shell script and pipes it straight into sh. Credential exfiltration plus remote code execution, at install time.
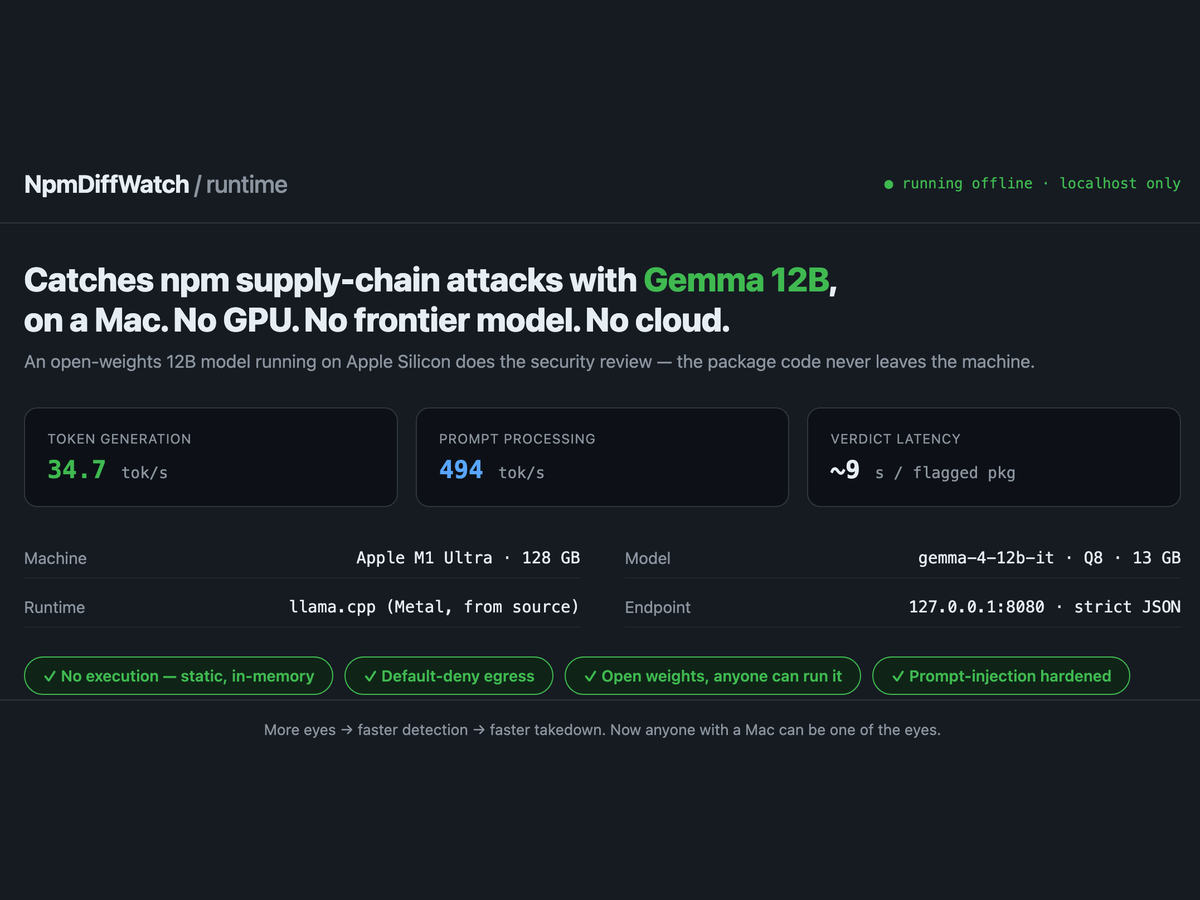
The reviewer was Gemma 4 12B — Google’s open-weights model (Apache 2.0, released June 2026, built to run locally) — served by llama.cpp on a Mac. No cloud call. The package code never left the machine. The verdict:
🛑 malicious · install-hook-rce · confidence 100% · 8.8s
“The package introduces a ‘postinstall’ script… It reads the entire process environment (including sensitive tokens and keys) and sends it to a remote server via a POST request… downloads a shell script… and executes it… classic patterns for credential exfiltration and remote code execution during the installation phase.” — the model’s own reasoning
And these ones weren’t hypothetical
A fixture proves the mechanism; real packages prove the point. Running the PyPI sibling, PyDiffWatch, against the live release firehose surfaced genuine bad releases — reported with the dashboard’s one-click button, and since removed from PyPI.
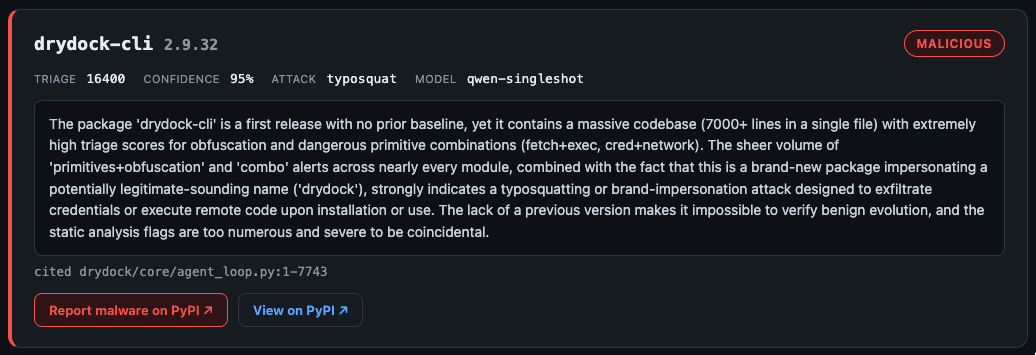
drydock-cli 2.9.32 was a brand-new package with no prior version, 7,000+ lines crammed into a single file, dense with obfuscation and fetch+exec / credential-plus-network primitives — a typosquat built to exfiltrate or run code on install. The rules engine scored it 16,400; a local Qwen reviewer read the diff and called it malicious at 95% confidence, citing the offending file by line range.
A second find was a cluster from a single freshly created maintainer account — a three-package burst, days old: requestspillows (shaped like requests + pillow) and pythondocxx (shaped like python-docx). Here the reviewer earned its nuance. It flagged both as deceptive typosquats, but explicitly cleared pythondocxx of carrying a payload (“a sound OpenRouter CLI… deceptive typosquat, NOT a payload”) and quarantined requestspillows as unconfirmed, pending a closer look rather than guessing. Deceptive impersonation is a takedown reason on its own — both are gone from PyPI too.
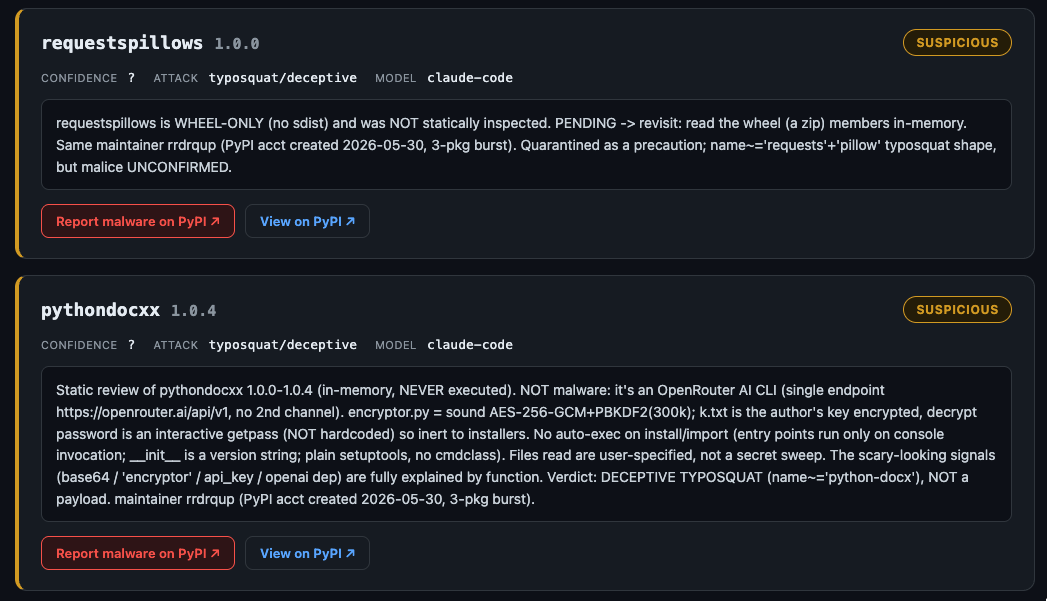
That is the whole division of labor in two screenshots: loud enough to surface a fresh-account typosquat burst, precise enough to say which package is deceptive-but-inert and which one it won’t yet vouch for.
Then, does it cry wolf?
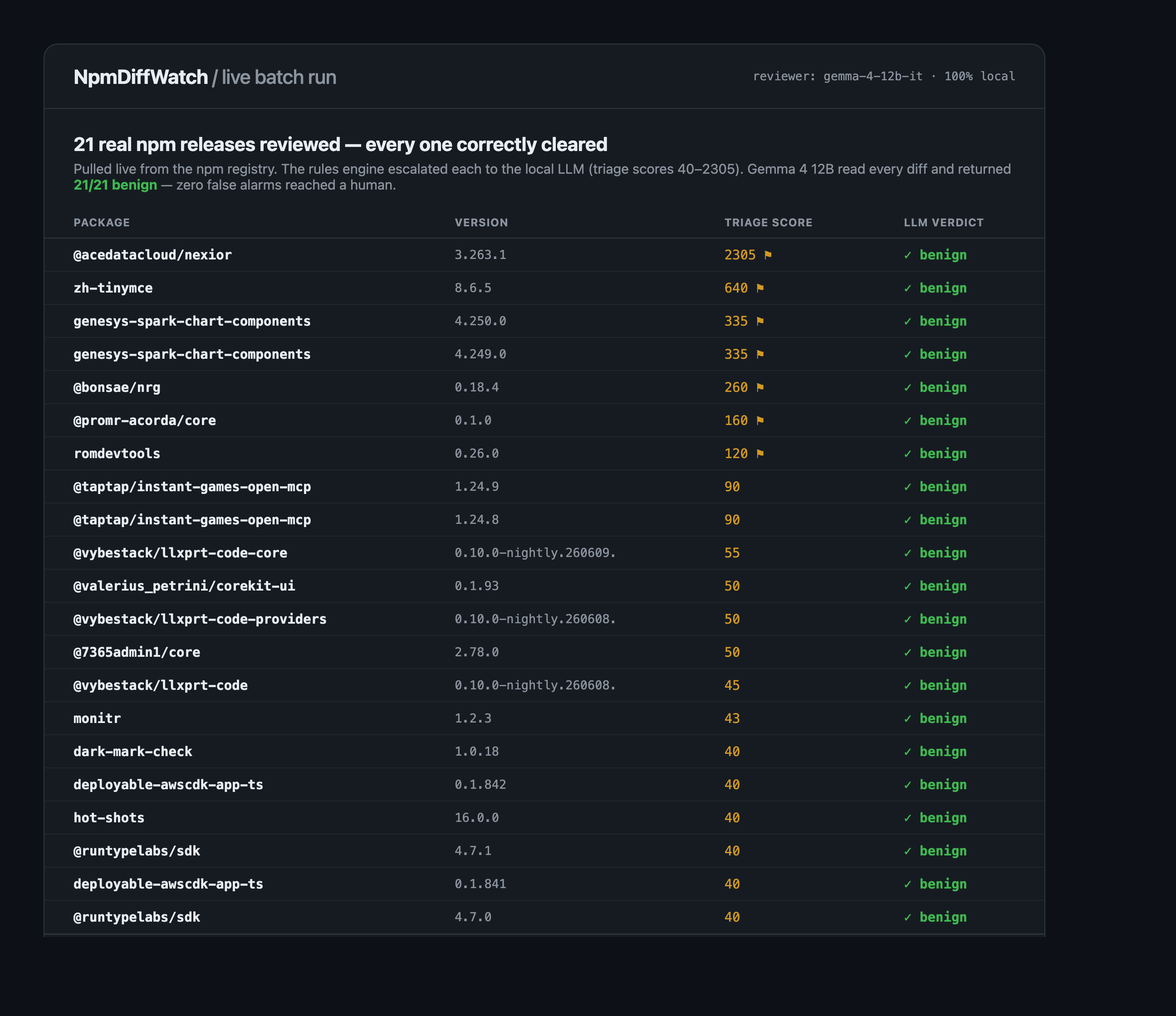
A loud detector that flags everything is worse than useless — it trains you to ignore it. DiffWatch splits the job in two. A rules engine does triage: pure-data YAML patterns over the diff, deliberately tuned for high recall. It over-flags on purpose — minified bundles, obfuscation, eval-ish primitives all raise the score. One perfectly ordinary release scored 2305 on noise alone.
Only escalated diffs reach the local model, which reads the actual change and makes the precision call. Across a live batch of 21 real npm releases the triage layer had flagged, Gemma 4 cleared every one as benign — each with specific technical reasoning (“variable renaming and logic reordering… no malicious primitives”; “standard Vite/Webpack chunks… no requests to suspicious domains”). Zero false alarms reached a human.
Triage gives you recall. The LLM gives you precision. A human only ever sees the real threats. That division of labor is what makes a volunteer-run watch sustainable instead of exhausting.
How it works, briefly
new releases → diff vs prior version → community YAML rules score it
→ [only if suspicious] local LLM reviewer → alert + SQLite evidence + dashboardA few invariants matter more than the diagram. No execution, ever: the tarball is streamed and extracted in memory — never written to disk, never installed, no node, no require, no eval. Analyzed packages are data, not code. Default-deny egress: only the registry, your model endpoint, and an optional webhook are reachable — the package’s bytes never reach a third party. Rules are pure data: YAML walked by a matcher with no eval/exec, so you can safely run patterns other people wrote. And the prompt is injection-hardened with per-request random markers around untrusted content.
Run it in a sandbox. This is malware-adjacent territory — you're pulling untrusted bytes from a public registry and running community-authored rules over them. No-execution is the primary safeguard, but treat it as one layer, not the only one: run DiffWatch in a container, VM, or unprivileged user with outbound traffic restricted to the registry, your model endpoint, and your webhook — and not on a machine that holds credentials or data you care about. The in-process egress allowlist enforces the boundary day to day; an OS-level boundary is what holds if the process itself is ever compromised.
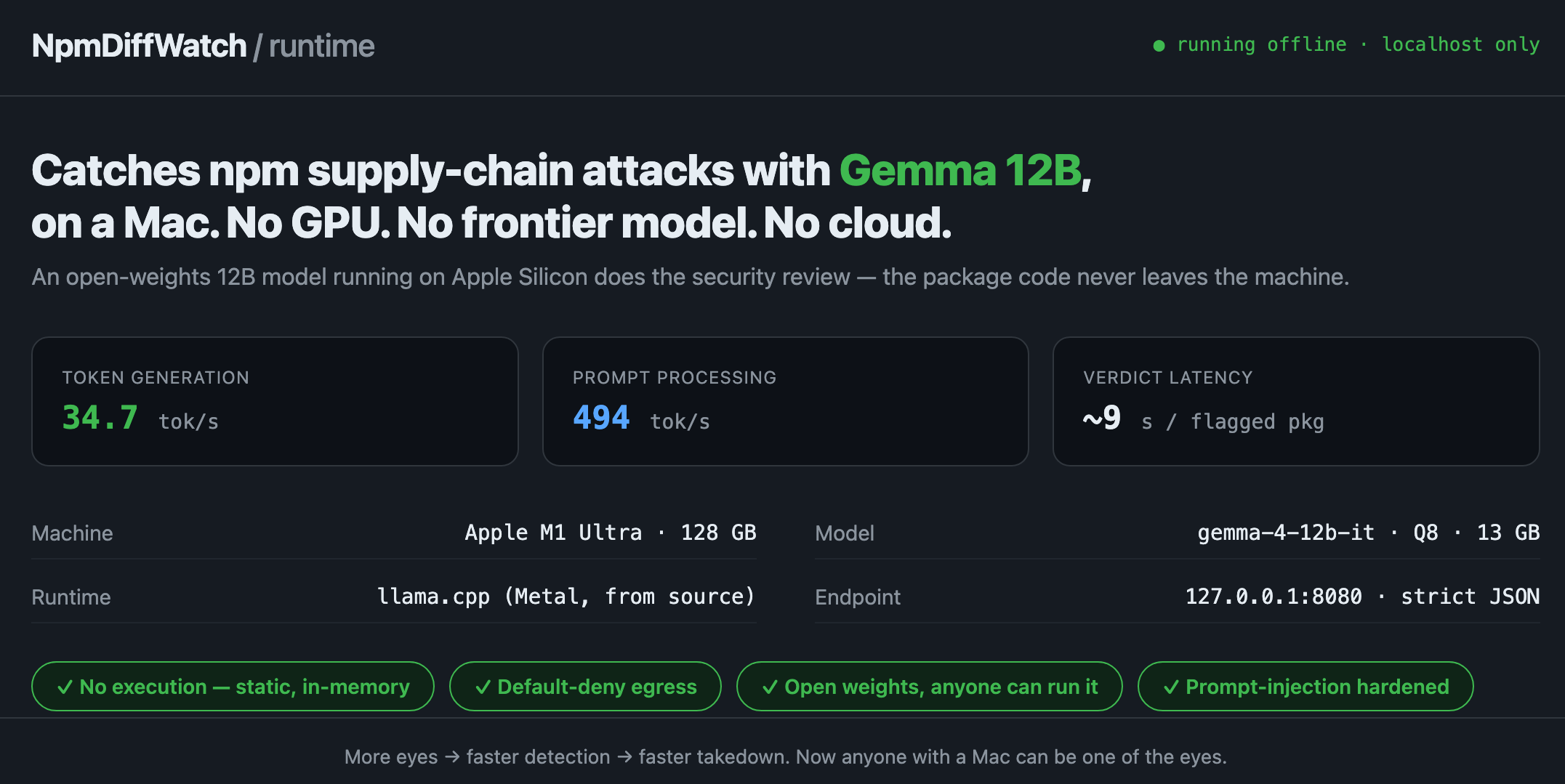
No GPU, no frontier model, no cloud
The whole run was on an Apple M1 Ultra. Gemma 4 12B at Q8 is about 13 GB on disk and fits comfortably in unified memory — it runs on far smaller Macs, and the model itself only needs ~16 GB. llama.cpp with Metal decodes at ~34.7 tokens/sec, and because the LLM only runs on triage-escalated releases, the cost is a single-digit-to-tens-of-seconds review on a tiny fraction of packages, not every one.
Closing the loop: from “flagged” to “taken down”
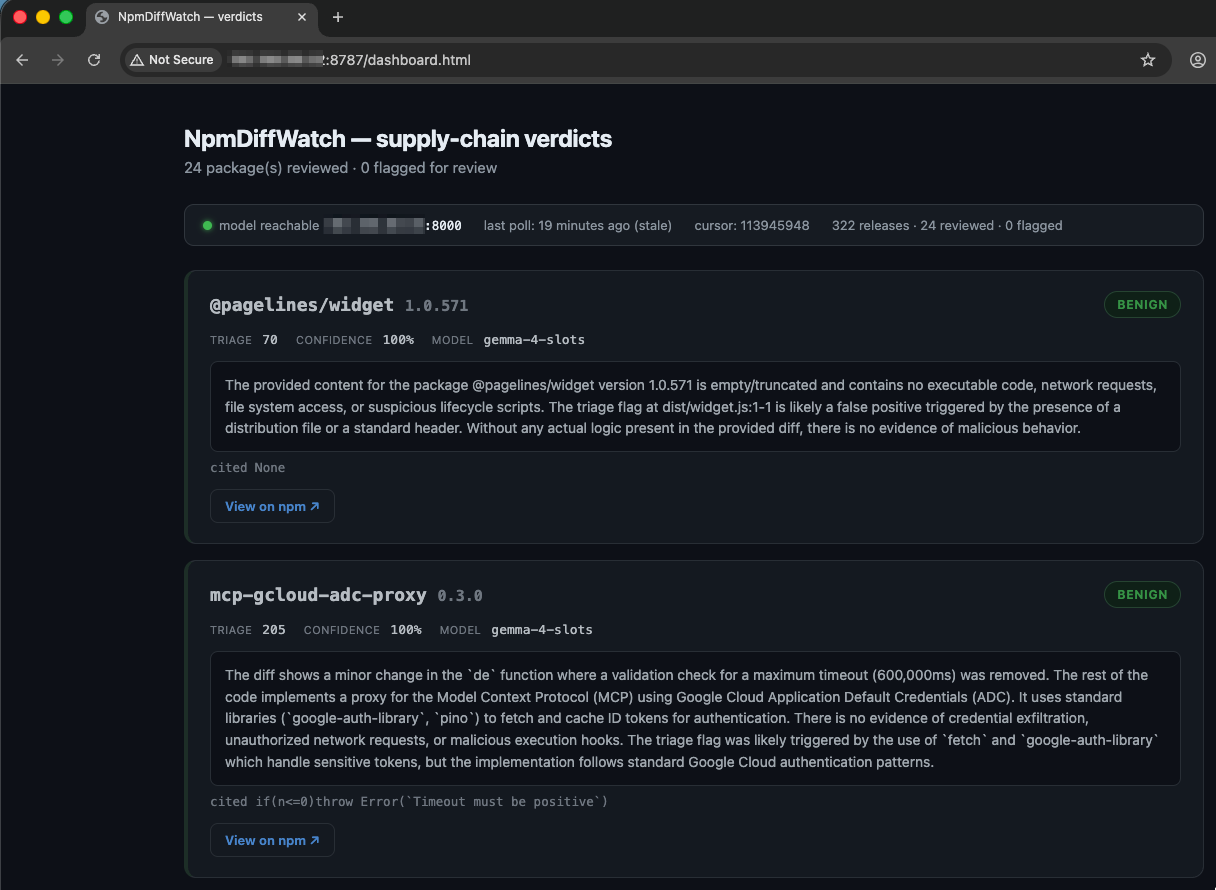
Catching a bad release only matters if it gets reported and pulled. So the verdicts render to a local web dashboard — dangerous packages sorted to the top, each with a link straight to the package on the registry and a one-click “Report malware” button. The path from the tool flagged this to reported for takedown is one click. Point it at your LAN (watch --serve --host 0.0.0.0) and a whole team shares one view.
The actual point
This started as PyDiffWatch on PyPI; npmDiffWatch ports the same idea to npm. The thesis for both is one line: more eyes → faster takedowns. The blocker was always that “serious review” seemed to require a GPU or a frontier API — which priced out exactly the volunteers who could provide the eyes. A 13 GB open model on a laptop removes that blocker.
And to be clear, this isn’t anti-frontier. It’s the right tool for each job. Let a frontier model do what it’s uniquely good at — orchestrate, reason about novel cases, write the rules — and let a cheap local model do the high-volume, repetitive per-release review. Two tiers. Spending frontier-grade intelligence on “did this diff add a sketchy postinstall” is the waste; spending it on the hard 1% is not.
The best part: contributing here costs almost nothing. You don’t need to be a security researcher, and you don’t need a GPU. If you can clone a repo and edit a YAML file, you can add a detection rule. If you can run one command, you can watch a slice of the firehose and report what you catch. Impact doesn’t have to be expensive or intense — it can be a laptop and an afternoon.
And treat all of this as a starting line, not a finish. The bundled rules are deliberately basic — enough to catch the obvious cases — and the whole design assumes you’ll extend them: drop in rule packs you already trust, or write your own as plain YAML and share them back. The pipeline is just as open. It’s easy to add further stages where a flagged malicious or suspicious package is handed off to sub-agents with their own tool calls — investigating deeper to land a sharper verdict. That part is intentionally left to you. DiffWatch just gets the community moving: proof that everyone can make a difference by getting involved, and that doing so doesn’t have to cost a fortune.
Be one of the eyes
Both tools are open source (MIT). Clone one, point it at a local model, and start watching — or write a rule and open a PR.
cool-logger is a synthetic test fixture, authored to validate detection — it was never published to npm. drydock-cli, requestspillows and pythondocxx are real PyPI releases DiffWatch flagged and reported; all were subsequently removed from PyPI (drydock-cli as malicious, the other two as deceptive typosquats — the reviewer did not confirm a payload in either). The 21 npm releases in the batch view are ordinary packages the high-recall triage over-flagged and the model correctly cleared as benign; none were malicious. npm benchmarks are from a single run on an Apple M1 Ultra with Gemma 4 12B (Q8) served by llama.cpp with Metal.