Diffusion LMs · Apple Silicon · MLX
The Chaos Engine: How Chunked Prefill Unmasked the Non-Linear Nature of Text Diffusion
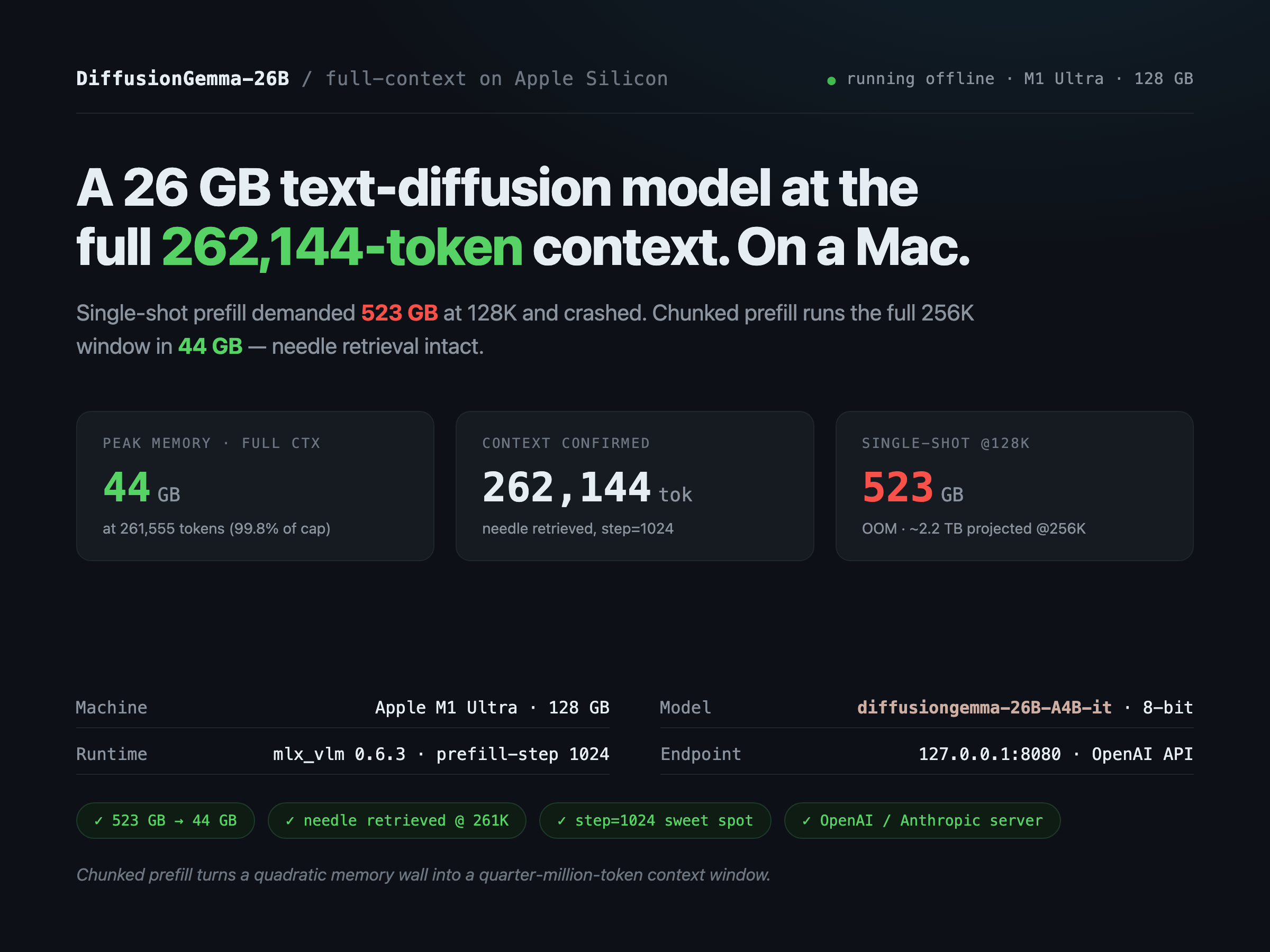
Running diffusiongemma-26B-A4B — a block-diffusion MoE — on a 128 GB M1 Ultra. A story that starts with a 523 GB memory request from a model that fits in 26 GB, and ends with a discovery about why diffusion language models don’t behave like the transformers we’re used to.
What I was trying to do
Google’s diffusiongemma is a different kind of language model. A normal LLM writes the way you read — left to right, one token at a time. A diffusion language model instead starts with a block of static and sharpens it over a few dozen passes, like a photo developing, until text emerges. It’s a genuinely new architecture, and I wanted to answer a simple question: can my Mac Studio run it at its full advertised context window — 262,144 tokens, roughly two novels of input?
The model is 26 GB on disk. The machine has 128 GB of memory. On paper, this should be comfortable.
A 26 GB model asked for half a terabyte
It wasn’t. Past about 32K tokens of input, memory exploded; at 128K tokens the model didn’t run out of memory so much as ask for an absurd amount of it — a single 523 GB allocation, four times the size of the entire machine, from a model that fits in 26 GB.
The short version of why: before a model can answer, it has to “read” your prompt (this stage is called prefill). Part of that reading involves a table that lets every token look at every other token — and that table grows with the square of the prompt length. Double the prompt, quadruple the table. At 128K tokens, the table alone is half a terabyte. The irony is that the layers responsible are the ones specifically designed to be memory-cheap — a fast path in the math library silently turns off for them, and nothing warns you.

The fix was already built in
The cure turned out to need zero code changes: instead of reading the whole prompt in one gulp, read it in pages — a built-in option called chunked prefill (prefill_step_size=1024). The giant table never forms, because no single pass is big enough to need it.
The same 128K prompt that demanded 523 GB now runs in 34 GB. The full 262K context — 99.8% of the model’s architectural maximum — runs in 44 GB, on a desktop Mac, offline. To verify it actually uses all that context (not just survives it), I buried a unique fact at the middle of a quarter-million-token document and asked for it at the end. The model retrieved it, every time, at every length I tested.
The surprise: the fix changes what the model says
Here’s where it gets interesting. Chunked prefill is supposed to be invisible — the same math, tiled differently, like reading a book in chapters instead of one sitting. On a normal LLM it produces identical output. I verified the model is fully deterministic: run the same prompt twice the same way, get the same answer, bit for bit.
But run it chunked vs. unchunked — or chunked with a different page size — and the model gives a different answer every time. Not a worse answer; each one was fluent, correct, on-topic. Just different.
The reason is the diffusion process itself. Tiling the reading changes the order of floating-point arithmetic, which shifts the model’s internal numbers by about one part in ten thousand — normally harmless rounding noise. A regular LLM shrugs that off. But diffusion generates by repeatedly re-sharpening its draft, deciding each pass which words it’s confident enough to commit. That feedback loop amplifies the rounding noise: a microscopic nudge flips which word locks in first, which changes the next pass, which cascades into a visibly different completion. A butterfly effect, in text. That’s the chaos engine.
The practical consequence: on diffusion models, performance knobs you’d treat as “free” can quietly change the output. If you benchmark one, compare output quality — never exact text.
The speed knob that does nothing (until it ruins everything)
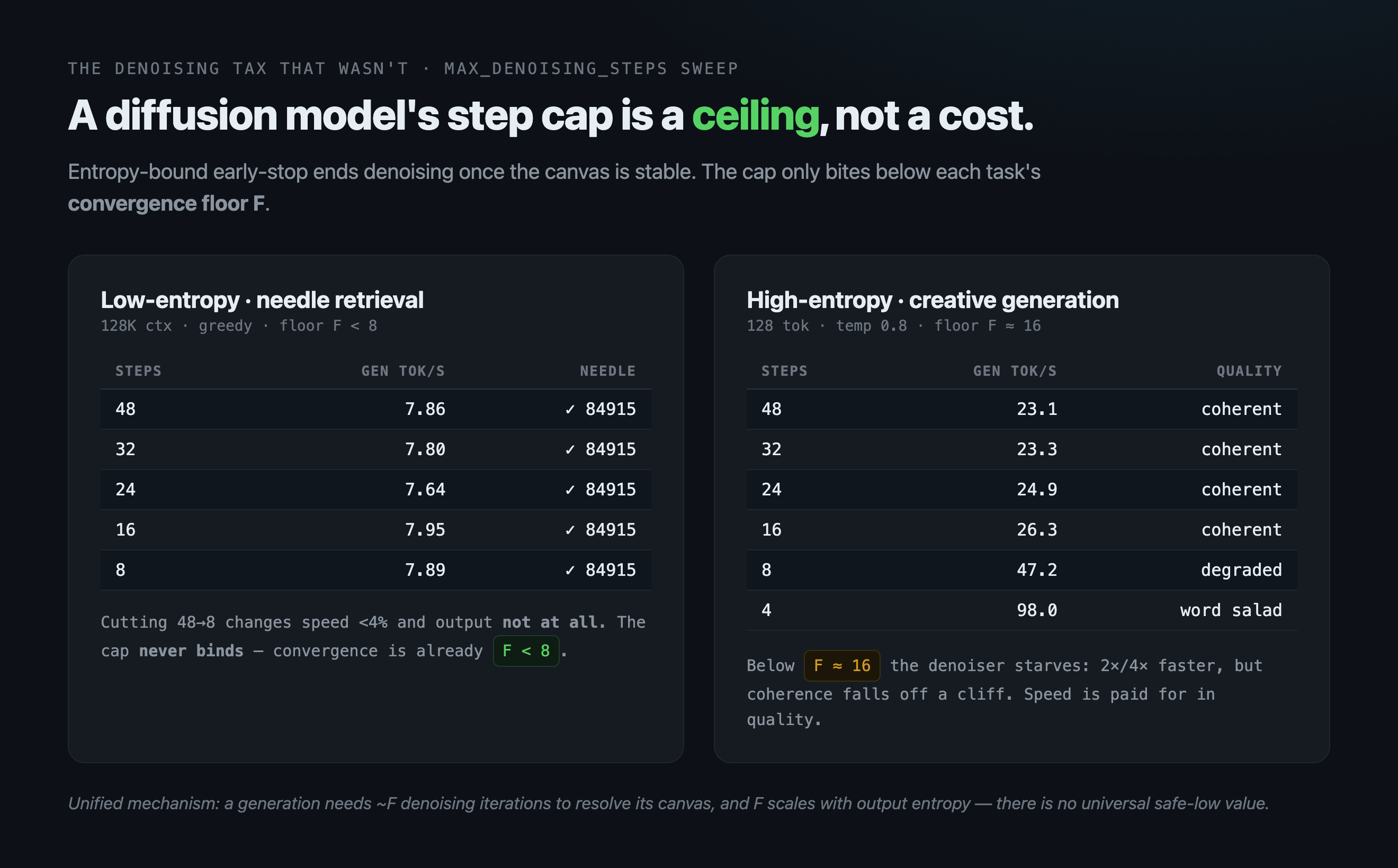
Diffusion models are supposedly slow because of all those sharpening passes — up to 48 per block here. So the obvious speedup is to cap them lower. I tested it: cutting the cap from 48 to 8 changed speed by less than 4% and the output not at all. The model already stops early the moment it’s confident — for easy answers it converges in a handful of passes, and the cap never comes into play.
But push the cap below what a task genuinely needs and the failure is total. On a creative-writing task, 16 passes produced fluent prose; 8 produced broken repetition; 4 produced word salad — at double and quadruple the speed. The speedups only exist where the output breaks.
What actually governs speed is prompt length — every sharpening pass re-reads the whole context, so generation slows as context grows. If you want faster output, the lever is a shorter prompt, not fewer passes.
What to take away
- New-architecture models often “don’t fit” for boring reasons. The 523 GB demand wasn’t the model’s size — it was one code path quietly falling off a fast path. One built-in parameter fixed it.
- A quarter-million-token context now runs on a desktop Mac — 44 GB of RAM, retrieval intact, fully offline. You can even serve it over a standard OpenAI-style API today.
- Diffusion LMs are numerically chaotic. Optimizations that are invisible on normal LLMs change a diffusion model’s output. Different isn’t worse — but it means “did the text change?” is the wrong regression test.
- Speed knobs can be quality dials in disguise. The denoising cap does nothing on confident output and destroys difficult output. Measure quality at every setting, not just throughput.
TL;DR
- Following the obvious serving path, a 26 GB model tried to allocate a 523 GB single tensor and crashed.
- The culprit was not the KV cache, not quantization, and not the attention mask. It was the sliding-window layers materializing a dense
[N, N]attention-score matrix during single-shot prefill, which silently knocks MLX’s fused/flash attention kernel off its fast path. - The fix needed zero code changes: chunked prefill (
prefill_step_size). 128K context went from 523 GB OOM crash → 34 GB peak. - The sweet spot is
prefill_step_size = 1024–2048(fastest, lowest memory). Avoid 8192. - The twist: chunking is supposed to be a pure memory-tiling trick that produces identical output. For this diffusion model it does not. Every chunk size produced a different (but equally coherent) completion — because the iterative denoising sampler is a sensitive, near-chaotic map that amplifies the tiny floating-point differences between chunked and full prefill. Autoregressive greedy decoding absorbs that noise; diffusion denoising amplifies it. That is the chaos engine.
The setup
| Machine | Apple M1 Ultra, 48 GPU cores, 128 GB unified memory, macOS (Darwin 25.5), Metal 4 |
| Metal limit | Max single GPU buffer = 86,586,540,032 bytes (~86.6 GB) — this number matters later |
| Model | mlx-community/diffusiongemma-26B-A4B-it-8bit |
| Architecture | DiffusionGemmaForBlockDiffusion — block-diffusion MoE, multimodal (gemma4 vision tower) |
| Shape | 30 layers (25 sliding-window window=1024, 5 full-attention), 128 experts top-8 (~4B active of 26B), 16 attn heads, max_position_embeddings = 262144 |
| Diffusion | up to 48 denoising steps per block, canvas_length = 256, entropy-bound sampler |
| Stack | mlx 0.31.2, mlx-vlm 0.6.3 (ahead of PyPI 0.6.2 — a dev build), vllm-mlx 0.3.0, transformers 5.8.0.dev0 |
Two facts to hold onto: the model weights are 26 GB on disk, and the machine has 128 GB. Nothing about this setup should ever ask for hundreds of gigabytes.
Act 1 — The official path blows up
The community “supported” way to serve this is rapid-mlx serve (which is just vllm_mlx.cli). The starting command looked reasonable:
rapid-mlx serve ./models/diffusiongemma-mlx-4bit \
--host 127.0.0.1 --port 8080 \
--ctx-size 32768 \
--enable-chunked-prefillThree problems before a single token was generated:
-
Wrong weights. There was no 4-bit copy on the host — only the 8-bit one in the HF cache.
-
Two invented flags.
--ctx-sizeand--enable-chunked-prefilldon’t exist. The real knobs are--chunked-prefill-tokens Nand--cache-memory-percent. -
The server can’t actually generate. With corrected flags it loads the model, then every decode step dies in a tight loop:
ERROR: Error in MLLM process loop: BatchRotatingKVCache._temporal_order() takes 1 positional argument but 2 were givenA signature-mismatch bug in
vllm_mlx’s continuous-batching scheduler against this model’s rotating KV cache. It loads the weights and produces nothing.
So I dropped to the reference path — mlx_vlm.generate — which works. And immediately hit a wall.
Act 2 — The quadratic wall
Single-shot prefill, measuring token speed and peak memory as context grows:
| Context | Prefill tok/s | Generation tok/s | Peak RAM |
|---|---|---|---|
| 256 | 224 | 16.8 | 30.6 GB |
| 20,725 | 696 | 14.3 | 31.2 GB |
| 32,425 | 302 | 6.0 | 72.2 GB |
| 48,000 | — | — | ❌ hard crash |
| 127,825 | — | — | ❌ 523 GB request |
48K died with an uncatchable C++ abort:
libc++abi: terminating due to uncaught exception of type std::runtime_error:
[METAL] Command buffer execution failed: Insufficient Memory
(kIOGPUCommandBufferCallbackErrorOutOfMemory)And 128K printed the number that started the whole investigation:
RuntimeError: [metal::malloc] Attempting to allocate 522855380000 bytes
which is greater than the maximum allowed buffer size of 86586540032 bytes.522,855,380,000 bytes = 523 GB. From a 26 GB model. On a 128 GB machine. The allocation is bigger than the machine, bigger even than Metal’s 86.6 GB per-buffer ceiling. Where does half a terabyte come from?
The number factors exactly:
127825 (tokens)² × 16 (heads) × 2 (bytes, bf16) = 522,855,380,000That is the shape of a dense [batch, heads, N, N] attention-score tensor. Something was materializing the full N×N attention matrix instead of streaming it.
Act 3 — The misdiagnosis, then the probe
First hypothesis (wrong): the model isn’t using flash attention; it builds an explicit attention mask that forces a dense softmax(QKᵀ). I even patched the mask builder to force the “fast path” for the trivial all-ones mask.
Result: no change. 32K still peaked at exactly 72.2 GB; 128K still asked for exactly 523 GB. When a patch changes nothing, the hypothesis is wrong. Stop guessing — instrument.
I added a one-shot probe to mlx_lm/models/base.py’s scaled_dot_product_attention to print, per call, which branch runs and what mask type it gets. On a small 2K context that doesn’t OOM:
[SDPA] quantized=False q_len=2001 k_len=2001 heads=16 mask=arr(2001, 2001):bool cache=RotatingKVCache
[SDPA] quantized=False q_len=2001 k_len=2001 heads=16 mask=str:causal cache=KVCacheThere it is. Two attention regimes:
- Global / full-attention layers (5):
mask="causal"— a string. MLX’smx.fast.scaled_dot_product_attentionrecognizes the causal string and uses its fused/flash kernel. Memory O(n). Fine. - Sliding-window layers (25):
mask=arr(N, N):bool— an explicit boolean array. An arbitrary array mask defeats the flash kernel; SDPA falls back to materializing the full[B, 16, N, N]scores. Memory O(n²).
Why does the sliding layer get an array? Because create_attention_mask returns a create_causal_mask(N, window) array whenever N > window (here window = 1024), and only returns the "causal" string otherwise:
# mlx_lm/models/base.py
if return_array or (window_size and N > window_size):
return create_causal_mask(N, window_size=window_size) # explicit array → no flash
return "causal" # string → flashWhat it is not:
- Not quantization — the probe says
quantized=False. The 8-bit weights don’t route attention through the quantized (materializing) path here. - Not the input
attention_mask— the diffusion harness already drops the trivial mask:decoder_attention_mask = attention_mask if has_padding else None. My earlier patch was redundant with code that already existed.
The irony writes itself: the sliding-window layers — the ones designed to be cheap at long context — are exactly the ones that blow up during prefill, because the window forces an explicit mask, and the explicit mask forces dense scores.
Act 4 — The fix: chunked prefill (no code changes)
If the disease is “a single forward pass over N tokens builds an [N, N] score tensor,” the cure is “don’t do a single forward pass over N tokens.” Process the prompt in chunks along the query dimension. The score tensor per chunk becomes [step, N] instead of [N, N].
And the mechanism is even nicer than just slicing: with step ≤ window (1024), every chunk has N ≤ 1024, so create_attention_mask returns the "causal" string even for the sliding layers → flash everywhere → the RotatingKVCache caps stored keys at the window. The dense [N, N] matrix never forms.
This is a built-in feature — prefill_step_size (CLI: --prefill-step-size). No patching:
generate(model, processor, prompt,
prefill_step_size=1024, # the entire fix
max_tokens=..., temperature=0.0)The result, on the exact 128K context that demanded 523 GB:
| Single-shot prefill | Chunked (step=512) | |
|---|---|---|
| 128K context | ❌ 523 GB OOM | ✅ 34.0 GB peak, 426 tok/s prefill, coherent output |
From a hard crash to 34 GB. The O(n²) compute is still there (chunking is sequential, so wall-clock prefill is minutes at 128K+), but the O(n²) memory is gone.
Act 5 — The sweet spot, and the chaos
To pick a step size I ran a sweep at 16K context with greedy, deterministic decoding, comparing both speed and the exact output text against a non-chunked full-prefill ground truth.
| step | peak | prefill tok/s | matches full-prefill output? |
|---|---|---|---|
| full (no chunk) | 42.7 GB | 489 | — (reference) |
| full (rerun) | 42.7 GB | 491 | ✅ identical (determinism confirmed) |
| 512 | 30.5 GB | 651 | ❌ |
| 1024 | 30.6 GB | 713 | ❌ |
| 2048 | 30.8 GB | 722 | ❌ |
| 4096 | 32.3 GB | 685 | ❌ |
| 8192 | 36.1 GB | 615 | ❌ |
Two findings.
The mundane one — the sweet spot. Throughput peaks at 1024–2048 and falls off on both sides (512 = too many tiny chunks; 8192 = the step × N score tensor grows and slows down, plus higher memory). Memory is trivial until 8192. Use prefill_step_size = 1024–2048.
The interesting one — the chaos. A full prefill rerun reproduces bit-for-bit (full == full#2 → determinism is real). Yet no chunk size matches the full-prefill output — not even step=512, which sits comfortably inside the window. And the chunked outputs differ from each other:
full: "... Mitochondria are the only organelles in"
step1024: "... Ribosomes are the only organelles in"
step4096: "... Most eukaryotic cells contain a"Chunked and full prefill are algebraically identical — but they accumulate the KV cache in a different floating-point reduction order. That produces differences on the order of 1e-4 in the logits. In a normal autoregressive model with greedy decoding, a 1e-4 nudge essentially never flips an argmax; the output is stable.
But this is a diffusion model. Generation isn’t a left-to-right argmax — it’s an iterative denoising loop (up to 48 steps per block) that decides which tokens to commit based on entropy thresholds. That loop is a sensitive dependence on initial conditions machine: a 1e-4 perturbation flips which token gets unmasked first, which changes the next denoising step, which cascades. Same prompt, same seed, same model — a different valid completion, purely because the prefill was tiled differently.
This is the headline. Chunked prefill didn't just fix memory; it acted as a perturbation probe that revealed the non-linear, chaotic character of text diffusion. Autoregressive transformers are (numerically) a stable map. Diffusion LMs are a chaotic one.
“Different” here does not mean “worse” — every output was equally fluent and on-topic — but it does mean you cannot treat prefill_step_size as a free, output-preserving speed knob the way you can on an AR model. The knob perturbs the sample.
Act 6 — Confirming the full 262,144-token context
The original goal: actually use the model’s full 256K context window on this machine. With chunked prefill the memory math is benign — at step, the global-layer score tensor is step × N × 16 × 2 bytes:
step=1024, N=262,144 → ~8.6 GBstep=2048, N=262,144 → ~17 GB
plus 26 GB weights and ~6 GB KV cache → comfortably under 128 GB.
To verify the model still uses the context (not just “doesn’t crash”), I ran a needle-in-a-haystack test: plant a unique fact — The Aurora Station access code is 84915 — at 50% depth in a document of fixed-width telemetry log lines, then ask for the code at the end. Retrieval counts only if 84915 appears in the greedy completion. I swept context length and step ∈ {1024, 2048}:
| step | Context | Peak RAM | Prefill tok/s | Gen tok/s | Retrieved? |
|---|---|---|---|---|---|
| 1024 | 230,523 | 42.2 GB | 305.9 | 5.8 | YES |
| 2048 | 230,523 | 50.2 GB | 299.9 | 5.6 | YES |
| 1024 | 248,935 | 43.3 GB | 286.6 | 5.5 | YES |
| 2048 | 248,935 | 51.9 GB | 284.2 | 5.4 | YES |
| 1024 | 261,555 | 44.0 GB | 262.0 | 5.2 | YES |
| 2048 | 261,555 | 53.0 GB | 279.7 | 5.1 | YES |
The needle survives all the way to 261,555 tokens — 99.8% of the model’s 262,144 architectural cap — at both chunk sizes. Chunked prefill does not break long-range retrieval. The single most important number in this whole investigation is in that last block: the full 256K context runs in 44.0 GB of RAM. To put that in scale, the same N²×16×2 dense-score formula that exactly predicted the 523 GB allocation at 128K projects to a ~2.2 TB score tensor at 262,144 tokens (262144² × 16 × 2 = 2,199,023,255,552 B) — single-shot prefill never gets close to running this context on any machine. (That 2.2 TB is a projection from the formula, not a measured allocation; single-shot OOMs long before, at 128K, where it did ask for a measured 523 GB — see Act 4 for the apples-to-apples 128K comparison: 523 GB OOM → 34 GB chunked.) Two more results jump out:
step=1024strictly dominatesstep=2048at long context. Identical retrieval, identical speed, butstep=2048costs +8–9 GB peak RAM (the score tensor scales linearly withstep). Beyond ~230K, larger chunks buy you nothing but memory pressure. The earlier sweep’s “1024–2048 tie” breaks in 1024’s favor once the context is huge.- Peak memory barely moves with context length — 42 GB at 230K, 43 GB at 249K — because the score tensor depends on
step, notN. This is the whole point of chunking: decouple memory from context length.
A note on the cap: hitting exactly 262,144 tokens took a calibration loop. Naïve token-count estimates undershot by ~5%; I re-tokenized and adjusted entry counts until the prompt landed at 261,555 — 99.8% of the cap, with room for the 24 generated tokens. As predicted, the full-cap row tracks the 249K row almost exactly (44.0 vs 43.3 GB peak), because at this scale memory is governed by
step, notN.
Act 7 — The denoising tax that wasn’t
Generation is slow — ~5 tok/s at full context, ~8 tok/s at 128K. The obvious culprit: this is a diffusion model with max_denoising_steps=48, so surely each block of output costs 48 forward passes, a ~48× tax over an autoregressive model’s one-pass-per-token decode. The obvious fix: turn the knob down.
I swept max_denoising_steps ∈ {48, 32, 24, 16, 8} at a fixed 128K context, holding prefill_step=1024 so only the denoising count varied:
| max_denoising_steps | Gen tok/s | Retrieved? | Output |
|---|---|---|---|
| 48 | 7.86 | YES | 84915 |
| 32 | 7.80 | YES | 84915 |
| 24 | 7.64 | YES | 84915 |
| 16 | 7.95 | YES | 84915 |
| 8 | 7.89 | YES | 84915 |
Cutting the cap 6× did nothing. Gen speed moved <4% (noise), and the output was byte-identical at every setting. The “48× tax” hypothesis is simply wrong — and the source says why.
This model ships confidence_threshold: 0.005 and stability_threshold: 1 in its generation_config.json, which activates mlx_vlm’s adaptive stop. The denoising loop (diffusion.py:866) is bounded by max_denoising_steps, but it breaks early (:1020) the instant _diffusion_stable_and_confident is true — the canvas hasn’t changed for stability_threshold iterations and mean token entropy has fallen below confidence_threshold. For a confident, low-entropy generation — retrieving a clear fact, answering with a short number — the sampler converges in a handful of steps, far below 8. So max_denoising_steps is a ceiling that never binds on easy generations. It’s not the realized step count; it’s a safety cap for the hard cases.
The real cost of generation is the per-pass attention over the KV cache, which is why gen throughput tracks context length, not step count:
| Context | Gen tok/s |
|---|---|
| ~16K | ~10.8 |
| ~128K | 7.9 |
| ~261K | 5.2 |
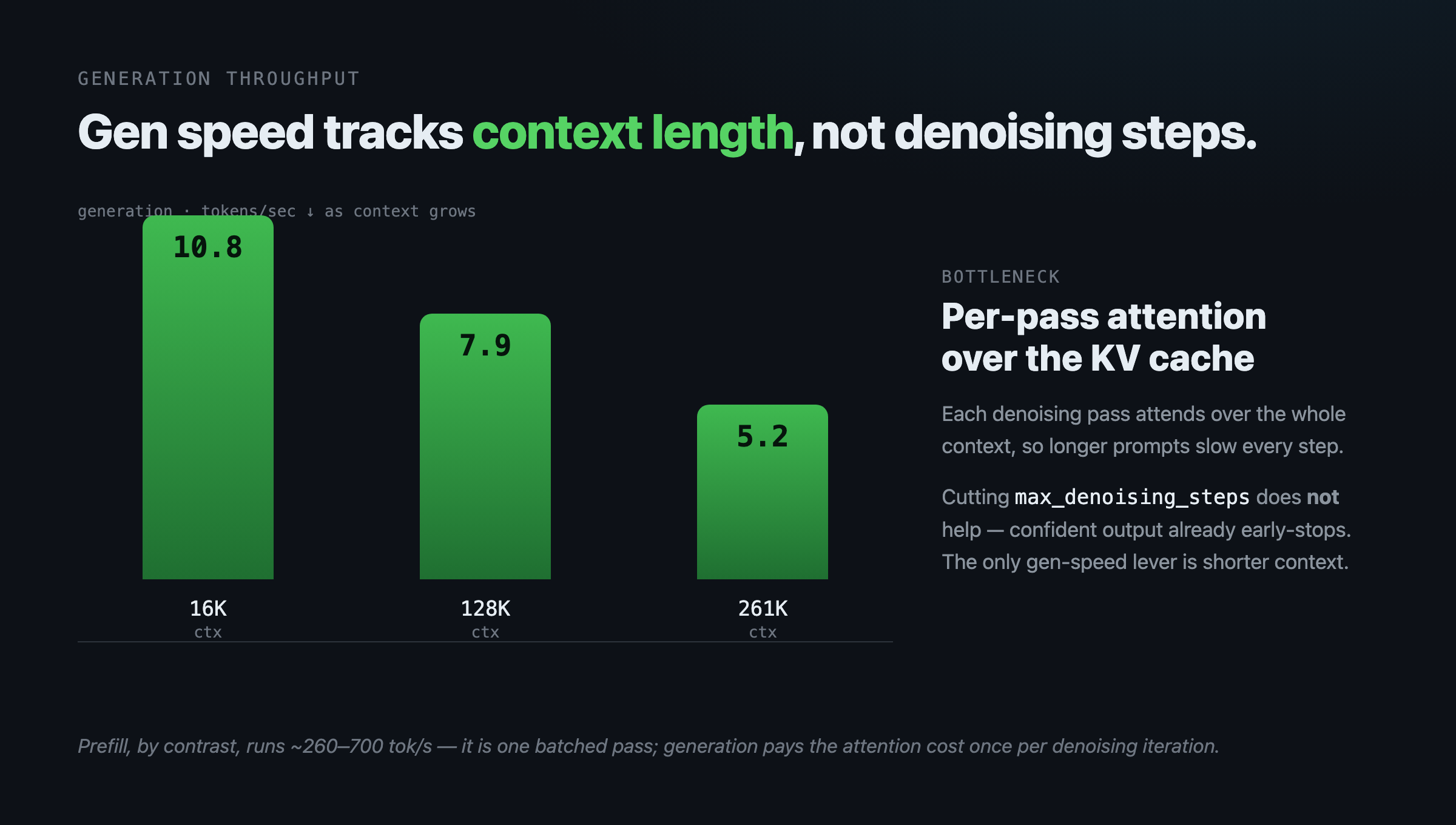
The lesson is the inverse of the intuition: you can’t make confident generation faster by cutting denoising steps, because the model already stopped early. But that raises the obvious question — when does the knob bite?
Where the cap does matter: the entropy-convergence floor
The needle task is low-entropy: a clear fact, a short number. To see the cap actually bind, I ran a high-entropy task — open-ended creative generation, 128 tokens, temperature=0.8, tiny context — and swept the same steps (adding 4):
| max_denoising_steps | Gen tok/s | Quality |
|---|---|---|
| 48 | 23.1 | coherent, vivid |
| 32 | 23.3 | coherent |
| 24 | 24.9 | coherent |
| 16 | 26.3 | coherent |
| 8 | 47.2 | degraded — repetition, broken grammar (of of of, It It a a a) |
| 4 | 98.0 | word salad — total collapse |
Sample at 48 steps: “…a colossal, translucent jellyfish drifted, defying gravity. Its tentacles glowed with a bioluminescent violet, humming a frequency that vibrated in Elias’s teeth…” — fluent and imaginative.
Sample at 4 steps: “…the fog was a a wool wool,, the the… the the the beam the… wasn’tt a a a a a a,,,,,,,,,,,” — the denoiser never resolved the canvas.
This is the exact mirror of the needle sweep, and the two together give one mechanism: the entropy-convergence floor. Every generation needs some number of denoising iterations to resolve its canvas; that number scales with the entropy of what’s being generated.
- Low-entropy (needle): floor is below 8 steps → caps of 8–48 all land past it → identical output, the cap never binds.
- High-entropy (creative): floor is ~16 steps → caps of 16–48 all converge cleanly (similar speed and quality), but caps of 8 and 4 clip below the floor → denoising is starved → speed leaps (2×, then 4×) and quality falls off a cliff.
So max_denoising_steps is inert until you push it under the task’s entropy floor — and past that line, every bit of speed is paid for directly in coherence. There is no universal “safe low value”: harder generation has a higher floor. And note where the big speed-ups live — 47 and 98 tok/s — precisely at the settings where the output broke. On confident generation the knob does nothing; on hard generation it’s a quality dial wearing a speed knob’s clothing.
If you want faster generation at long context, the lever is the context itself (attention cost per pass), not the denoising schedule.
Lessons
- A number that factors is a number that confesses.
523 GB = N² × heads × 2told us it was a dense score tensor before reading a line of source. Always factor the allocation. - When a patch changes nothing, the hypothesis is wrong. Stop theorizing and instrument. A six-line print in the SDPA dispatch settled in one run what three rounds of source-reading couldn’t.
- Not all “servers” are equal — test the specific one.
rapid-mlx serve(vllm_mlx) had invalid flags in the wild and a scheduler bug (_temporal_order) that made generation impossible. Butmlx_vlm.server— a different codebase — runs the same model fine over an OpenAI/Anthropic-compatible API (verified: peak 29.8 GB, correct output). Don’t generalize one server’s failure to “no serving support.” Caveat:mlx_vlm.serverserializes concurrent requests (2 concurrent ≈ 2× wall time) — it serves, but it doesn’t parallelize diffusion on a single GPU. - Flash attention is fragile to mask representation. A
"causal"string flashes; an equivalent boolean array does not. Sliding-window layers tripped this precisely because the window forces an explicit mask. - Chunked prefill fixes memory, not compute. O(n²) FLOPs remain; long-context prefill is minutes, not seconds. Plan for it.
- Diffusion LMs are numerically chaotic. The same speed/memory optimization that is output-neutral on an AR transformer will change the generated text on a diffusion model. Benchmark quality, not just throughput — and don’t use exact-match as your quality metric, because even valid recomputations won’t match.
max_denoising_stepsis a ceiling, not a cost. With entropy-bound early stopping active (this model’s default), confident generations converge in a few steps and ignore the cap. Don’t assume “diffusion = N forward passes per token”; measure the realized step count before treating it as a speed knob. The real gen cost here is per-pass attention over the KV cache, which scales with context length, not with the denoising cap.
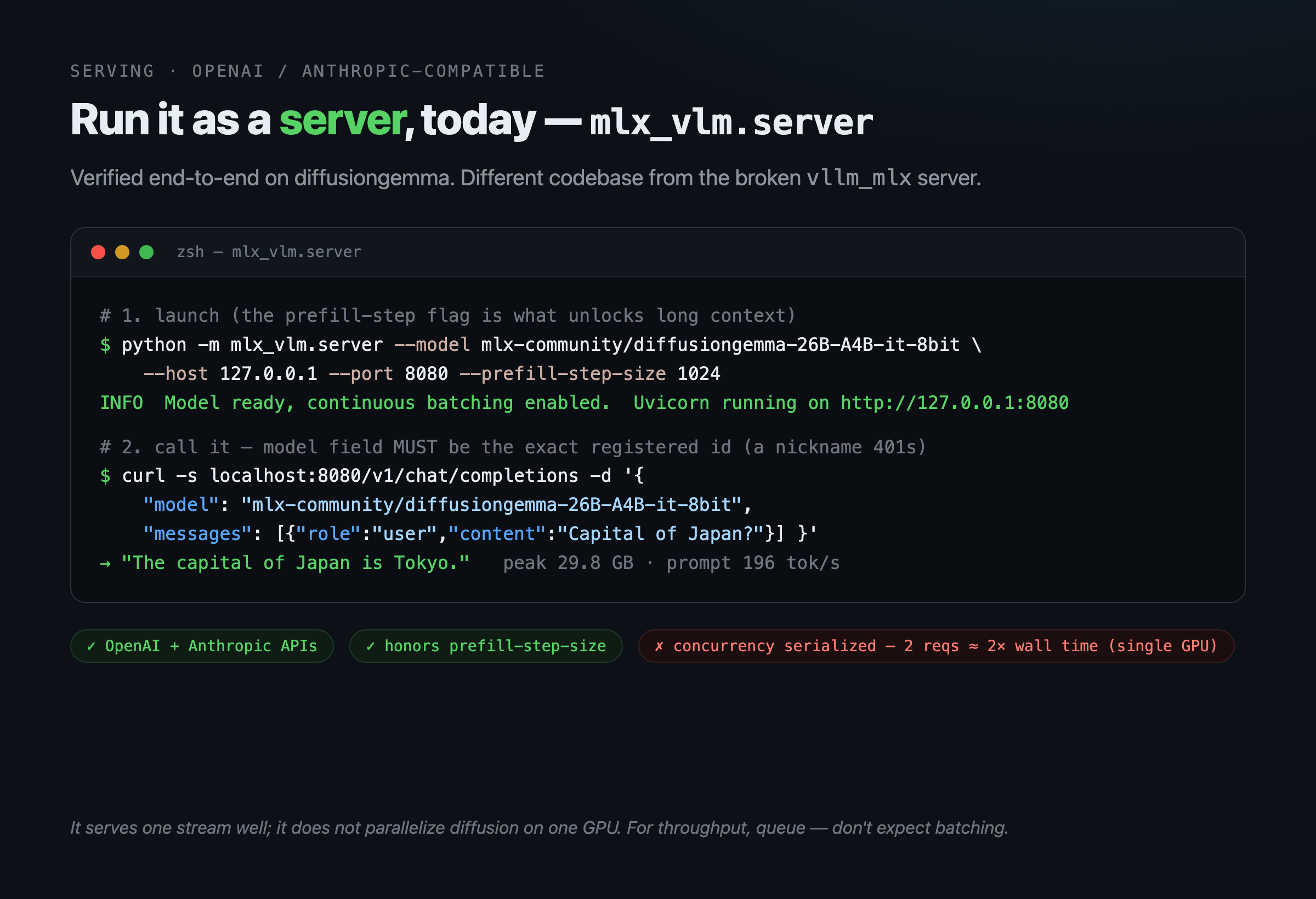
mlx_vlm.server, OpenAI/Anthropic-compatible, honors chunked prefill. One stream at a time.Recommended configuration
from mlx_vlm import load, generate
model, processor = load("mlx-community/diffusiongemma-26B-A4B-it-8bit")
out = generate(
model, processor, prompt,
prefill_step_size=1024, # 1024 wins at long ctx: same speed as 2048, ~8-9 GB less peak RAM
max_denoising_steps=48, # ceiling only; entropy-bound stop converges early on confident output
temperature=0.0,
)
# Avoid single-shot prefill above ~32K (O(n²) score-tensor OOM).
# Avoid step >= 8192 (bigger score tensor, slower, more memory).
# Expect long-context prefill to be compute-bound (minutes), not memory-bound.
# Don't cut max_denoising_steps for speed on confident generations — it already early-stops below the cap.Every number in this post comes from instrumented runs on the machine in the setup table — greedy decoding unless stated, peak RSS measured per run.